by Mawer Investment Management, via The Art of Boring Blog
The effects of machine learning are all around us: email spam filters, driverless cars, voice recognition software (hi, Alexa) and even movie recommendation sites like Rotten Tomatoes. Technology is certainly changing the investing landscape.
Naturally, many now wonder whether man or machine will come out on top. But this dichotomous framing is too narrow and misses an opportunity. Humans and machines have different strengths and weaknesses, and on our team, we tend to see the foreseeable future as a world in which the two work side-by-side. As with any tool, for machine learning to be useful, it is what it is being used for and how that matters.
How Machine Learning works
Machine learning can be likened to training a student to become the best chess player. Imagine you placed a student in a room with just a chessboard and a set of instructions:
- The rules of chess
- What constitutes a win
- Thousands of chess game examples
After a few days (she’s very bright), sleepless nights, and many cups of coffee, the student comes back with the following announcement: she has figured out all the moves that maximize the probability of winning. How? By studying the data, hypothesizing potential moves, testing these moves, and learning lessons over thousands of experiments.
This would be similar to how a machine learning algorithm might work. The goal of machine learning is for a computer to learn to perform and improve on specific tasks without being explicitly programed. In most applications of machine learning the data set is not generated by the algorithm, but provided by its creator.[1] The machine learning process starts with the user receiving and preparing the data, then a machine learning algorithm trains the model, tests the data and, ultimately, learns.
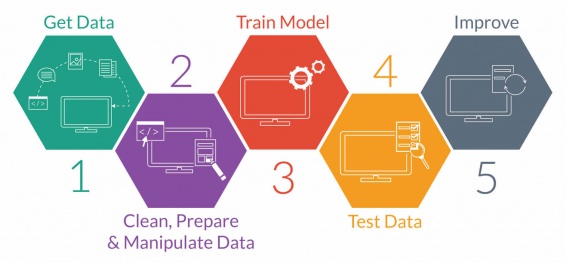
‘Predictive modeling.’ source: UPX academy
In business, machine learning is often used in conjunction with data mining and modeling for predictive analysis. For example, most of us have shopped online, only to have the website recommend another (eerily appropriate) product. When this happens, it is a machine learning algorithm operating behind the scenes. The algorithm is examining your profile, the composition of your basket, and what other customers have bought after purchasing the same items in your basket. As the data accumulates (both yours and other individuals’ shopping history), the machine gets better at making recommendations of items you might like to buy.
Machines are good at quickly processing massive and broad data sets—much more so than we are. However, they tend to shine when there are:
- Good quality and quantity of data
- Many experiments with short cycle length
- Rule/ecosystem stability (in many cases)
Just the data, Ma’am
When it comes to machine learning, data is incredibly important—more so than the machine learning algorithm itself. As our colleague Justin Anderson pointed out in The age of data monopolies, algorithms are becoming increasingly commoditized. What matters is “the amount, granularity, and exclusivity of the data you have.” He points out the best facial recognition software will be the one with access to the most faces and varied renderings of those faces (e.g., angles, lighting).
Data quantity and quality are crucial because both elements influence signalling. For a machine to learn effectively, it must be fed enough good data. And what do we mean by “good” data? We mean data that allows the machine to have the necessary ingredients to unearth the real causal relationships that exist.
As an example, let’s imagine you are an investor in Tim Hortons and want your machine to determine the factors that drive coffee purchases in Canada. A quality data set relating to coffee might include such variables as: the price of coffee, the price of coffee substitutes, Canadian incomes, distance to coffee locations, among others. By feeding the machine this information, you would hope to better understand what factors truly drive coffee purchase volumes.
Importantly, quality data is as much about what you don’t include as what you do include. For example, you might not want to include all the economic data from China in your coffee model because this would risk spurious correlation—when the computer finds a pattern that exists, but it’s not indicative of a causal relationship. An example of spurious correlation would be if the machine discovered a correlation between Chinese diaper and Saskatchewan coffee sales. Similarly, omitting unnecessary variables is also important, otherwise there is a risk of overfitting the model. Overfitting occurs when there are too many parameters and the model fits too closely to the training data but would fail to reliably predict future observations.
The more, the faster, the better
Another key consideration is cycle time. Machine learning is most effective when cycle times are short and when there are multiple experiments running concurrently. The shorter the cycle length, the faster the computer is going to learn and improve. More experiments also lead to a better understanding of its environment.
Chess-playing machines demonstrate this well. They can play thousands of games simultaneously and quickly. The high number of games and short cycle time allow the chess machine learning algorithm to gather a significant amount of data rapidly and play better.
In comparison, the cycle time in investing applications can really vary, and depending on what we are trying to investigate, can be much longer. For example, the impact of e-commerce on the return on invested capital (ROIC) of brick and mortar retailers and mall operators might not be a good problem to give to a machine learning algorithm if we are dealing with only one cycle and that cycle is quite long. A mall operator would need to know that the relationship could be ruinous before the cycle completes.
When a + b ≠ c
Finally, machine learning is better at solving problems where the rules of the game don’t change, or change slowly. In other words, where there is some constancy of the system’s structure. Clearly, this is the case in chess, where a pawn is not suddenly allowed to go rogue and jump five spaces left. But this kind of rule premanence doesn’t always exist.
Investing is one of the applications when the rules of the game can change fast. For example, new technologies are regularly invented that disrupt the normal flow of industry dynamics and consumer behaviours, generally altering previous economic relationships. Likewise, regulations evolve in ways that materially impact the way that business is conducted (e.g., tax, trade). Even fairly stable concepts like nation-states can evolve over time through war, annexation or movements like Brexit. In investing, there is always some risk that a machine will fail to appreciate important step changes. This is something architects of these programs would want to be aware. We find that when there’s a fast change in the rules, machines and humans may need to work together.
While there are many who argue for and against machine learning in investing, we view this as an unnecessary and false dichotomy. Our team believes that in the foreseeable future machine learning tools and humans will work side-by-side, leveraging the strengths and covering the weaknesses of the other. Humans can be highly creative and entrepreneurial problem-solvers, but we also have clear biases and processing limitations. Machine learning may complement our weaknesses, particularly when conditions are primed for it (i.e., when there is enough quality data, cycle lengths are short, and the rules [in most cases] aren’t changing too much or too rapidly).
Certainly, there are limitations to using machine learning as a standalone tool for investing. For now, finding the right balance between human and machine is what will help investors stay agile in a fast-changing world with many different variables and limited data sets.
Of course, this is what we know about machine learning today. We have yet to see what the future holds.
[1] There are many ML algorithms for chess. Some algorithms, such as Alpha Zero, generate their own data sets.
This post was originally published at Mawer Investment Management